Advanced Programming in the UNIX Environment (Chapter4)
by4 - Files and Directories
Makefile for this chapter Makefile
Previous chapter was related to manage files through I/O functions for regular files (opening file, read it, writing). Now we will look to features of file system and properties of a file. We’ll start with stat functions, and go through each m
stat, fstat, fstatat and lstat Functions
discussion in this chapter centers on four stat functions and information they return:
#include <sys/stat.h>
int stat(const char *restrict pathname, struct stat *restrict buf);
int fstat(int fd, struct stat *buf);
int lstat(const char *restrict pathname, struct stat *restrict buf);
int fstatat(int fd, const char *restrict pathname, struct stat *restrict buf, int flag);
All four return: 0 if OK, -1 on error
Given pathname, stat function returns structure of information about named file. fstat function obtains information about file that is already opened on file descriptor fd (better to avoid TOCTTOU vulnerabilities). lstat function similar to stat, but when named file is symbolic link, lstat returns information about symbolic link, not file referenced by symbolic link.
fstat function provides a way to return file statistics for a pathname relative to open directory represented by fd argument. flag argument controls whether symbolic links are followed; when AT_SYMLINK_NOFOLLOW flag is set, fstatat will not folllow symbolic links, rather returns information about the link itself. Otherwise, default is to follow symbolic links, returning information about the file to which symbolic link points. If fd argument has value AT_FDCWD and pathname argument is relative pathname, then fstatat evaluates pathname argument relative to “current working directory”. If pathname is absolute pathname, then fd argument is ignored. These two cases, fstatat behaves like wither stat or lstat, depending on value of flag.
buf argument is a pointer to a structure that we must supply. Functions fill in structure. Definition of the structure can differ among implementations but looks like:
struct stat {
mode_t st_mode; /* file type & mode (permissions) */
ino_t st_ino; /* i-node number (serial number) */
dev_t st_dev; /* device number (file system) */
dev_t st_rdev; /* device number for special files */
nlink_t st_nlink; /* number of links */
uid_t st_uid; /* user ID of owner */
gid_t st_gid; /* group ID of owner */
off_t st_size; /* size in bytes, for regular files */
struct timespec st_atim; /* time of last access */
struct timespec st_mtim; /* time of last modification */
struct timespec st_ctim; /* time of last file status change */
blksize_t st_blksize; /* best I/O block size */
blkcnt_t st_blocks; /* number of dis blocks allocated */
};
st_rdev, st_blksize, and st_blocks fields are not required by POSIX.1. They are defined as part of XSI option in single UNIX Specification.
timespec structure type defines time in terms of seconds and nanoseconds. It includes at least the following fields:
time_t tv_sec;
long tv_nsec;
Prior to 2008 version, the time fields were named st_atime, st_mtime, and st_ctime, and were time_t (expressed in seconds). timespec structure enables higher-resolution timestamps. Old names can be defined in terms of tv_sec member for compatibility. Example, st_atime can be defined as st_atim.tv_sec.
Most members of stat structure are specified by primitive system data type. Biggest user of stat functions is probably “ls -l” command to get information about a file.
File types
We’ve talked about two types of files: regular files and directories. Most files on UNIX system are either regular or directories, but there are additional:
- Regular file. Most common, contains data of some form. No distinction to UNIX kernel whether this data is text or binary. Any interpretation of contents of regular file is left to application processing the file. One exception are binary executable files. As kernel must understand format to execute it. So all binary executable files conform to a format that allows kernel to identify where to load program’s text and data.
- Directory file. File that contains names of other files and pointers to information on these file. Any process that has read permission for a directory can read contents of directory, but only kernel can write directly to a directory file. Processes must use functions described later to make changes to a directory.
- Block special file. Type of file providing buffered I/O access in fixed-size units to devices such as disk drives. (FreeBSD no longer supports block special files. All access to devices is through characters special interface).
- Character special file. Type of file providing unbuffered I/O access in variable-sized units to devices. All devices on a system are block special or character special files.
- FIFO. Type of file used for communication between processes. Sometimes called named pipe. We describe FIFOs in Chapter 15.
- Socket. Type of file used for network communication between processes. Socket can also be used for non-network communication between processes on single host. We use socket for interprocess communication in Chapter 16.
- Symbolic link. Type of file that points to another.
Type of a file is encoded in st_mode member of stat structure. We can determine file type with macros:
S_ISREG() Regular file
S_ISDIR() Directory file
S_ISCHR() Character special file
S_ISBLK() Block special file
S_ISFIFO() pipe or FIFO
S_ISLNK() Symbolic link
S_ISSOCK() socket
Parameter of each macro is the st_mode member.
POSIX.1 allows implementations to represent interprocess communication (IPC) objects, suck as message queues and semaphores, as files. Next macros allow us to determine type of IPC object from stat structure. Instead of taking st_mode member as argument, these macros differ from previous in that their argument is a pointer to stat structure:
S_TYPEISMQ() message queue
S_TYPEISSEM() semaphore
S_TYPEISSHM() shared memory object
Discussed most in chapter 15. But None of implementations of these objects are as files in this book.
Example: type_printer.c program which prints type of file for each command-line argument.
Historically, early versions of UNIX System didn’t provide S_ISxxx macros. Instead we had to AND the st_mode value with S_IFMT and then compare result with constants whose names are S_IFxxx. Most system define this mask and related constants in file <sys/stat.h>. If we examine this file, we’ll find the S_ISDIR macro defined something like:
#define S_ISDIR(mode) (((mode) & S_IFMT) == S_IFDIR)
Regular files are predominant, but it is interesting to see what percentage of files on given system are of each file type.
Set-User-ID and Set-Group-ID
Every process has six or more IDs associated with it:
real user ID & real group ID = who we really are effective user ID, effective group ID & supplementary group IDs = used for file access permission checks saved set-user-ID & saved set-group-ID = saved by exec functions
- real user ID and real group ID identify who we really are. Taken from our entry in password file when we log in. Normally, values don’t change during a login session, although there are ways for a superuser process to change them.
- effective user ID, effective group ID, and supplementary group IDs determine our file access permissions.
- Saved set-user-ID and saved set-group-ID contain copies of effective user ID and effective group ID, respectively when a program is executed. These were optional in older versions of POSIX. Application can test for constant _POSIX_SAVED_IDS at compile time or can call sysconf with _SC_SAVED_IDS argument at runtime, to see whether implementation supports this feature.
Normally, effective user ID equals real user ID, and effective group ID equals to real group ID. Every file has owner and a group owner. Owner is specified by st_uid member of stat structure; group owner, by st_gid member. When we execute a program file, usually happen what we said about user and group ID. However we can set a special flag in file’s mode word (st_mode) that says, “When file is executed, set effective user ID of process to be owner of the file (st_uid).” We can set another bit in file’s mode word that causes effective group ID to be group owner of file (st_gid). These two bits in file’s mode word are called set-user-ID bit and set-group-ID bit.
If owner of file is superuser and if file’s set-user-ID bit is set, while program file is running as process, it has superuser privileges. And happens regardless of real user ID of process that executes the file. As example, UNIX System program that allows anyone to change his or her password, passwd(1), is set-user-ID program. Required so that program can write new password to file, typically /etc/passwd or /etc/shadow writable only by superuser. These kind of programs must be written carefully. We’ll discuss these types of programs in more detail in Chapter 8.
Returning to stat function, set-user-ID bit and set-group-ID bit are contained in file’s st_mode value. These two bits can be tested against constants S_ISUID and S_ISGID respectively.
File Access Permissions
st_mode value also encodes access permission bits for file. When we say file, any type. There are nine permission bits for each file, divided into three categories:
| type | meaning |
|---|---|
| S_IRUSR | user-read |
| S_IWUSR | user-write |
| S_IXUSR | user-execute |
| S_IRGRP | group-read |
| S_IWGRP | group-write |
| S_IXGRP | group-execute |
| S_IROTH | other-read |
| S_IWOTH | other-write |
| S_IXOTH | other-execute |
Term user in first three rows = owner of file. chmod command, typically used to modify these nine permission bits, allows us to specify ‘u’ for user (owner), g for group, and o for other. We’ll use terms user, group and other, to be consistent with chmod. The three categories - read, write, and execute - are used in various ways by different functions. We’ll summarize them, and return when we describe the actual functions:
- first rule is whenever we want to open any type of file by name, we must have execute permission in each directory mentioned in the name, including current directory. This is why execute permission bit for directory is often called search bit. Example opening file /usr/include/stdio.h needs permission of execute in /, /usr and /usr/include, also necessary have specific permission in stdio.h depending we are opening file in read-only or read-write, etc. If we are in /usr/include means we need execute permission in current directory to open file stdio.h. Read permission for a directory and execute permission for a directory mean different things. Read permission lets us read directory, obtaining list of all filenames in directory. Execute permission lets us pass through directory when it’s a component of a pathname we are trying to access. Another example of implicit directory PATH environment variable, specifies directory that does not have execute permission enabled. This case, shell will never find executable files in that directory.
- read permission for a file determines whether we can open existing file for reading: O_RDONLY and O_RDWR flags for open fnuction.
- Write permission for a file determines whether we can open existing file for writing: O_WRONLY and O_RDWR flags for open function.
- We must have write permission for a file to specify O_TRUNC flag (as remove content).
- We cannot create new file in directory unless we have write permission and execute permission in directory.
- To delete existing existing file, we need write permission and execute permission in directory containing the file. We do not need read permission or write permission for file itself.
- Execute permission for a file must be on if we want to execute file using any of seven exec functions. File also has to be a regular file.
File access tests that kernel performs each time a process opens, creates, or deletes a file depend on owners of file (st_uid and st_gid), effective IDs of process (effective user ID and effective group ID), and supplementary group IDs of the process, if supported. Two owner IDs are properties of the file, whereas two effective IDs and supplementary group IDs are properties of the process. Test performed by kernel are as follows: * If effective user ID of process is 0 (superuser), access is allowed. This gives superuser free rein throughout entire file system. * If effective user ID of process equals owner ID of file (process owns file), access is allowed if appropiate user access permission bit is set. Otherwise, permission is denied. By appropiate access permission bit, we mean that if process is opening file for reading, user-read bit must be on. Same with writing and executing. * If effective group ID of process or one of supplementary group IDs of process equals group ID of the file, access is allowed if appropiate group access permission bit is set. Otherwise, permission is denied. * If appropiate other access permission bit is set, access is allowed. Otherwise, permission is denied.
These steps are tried in sequence. Note if process owns file (step 2), access is granted or denied based only on user access permissions; group permissions are never looked at. Similarly, if process does not won file but belongs to appropiate group, access is granted or denied based only on group access permissions; other permissions are not looked at.
Ownership of New Files and Directories
We didn’t say values assigned to created files (by open or creat) for the user ID and group ID. We’ll see how to create a directory with mkdir. Rules for ownership of directory are the same than for a file. User ID of new file is set to effective user ID of process. POSIX.1 allows an implementation to choose one of following options to determine group ID of new file: * Group ID of new file can be effective group ID of process. * Group ID of new file can be group ID of directory in which file is being created. (FreeBSD 8.0 and Mac OS X 10.6.8 always copy new file’s group ID from directory. Several Linux file system allow choice between two options to be selected using a mount command option, Linux 3.2.0 and Solaris 10 determine group ID if bit SGID (set-group-ID) is set new file’s group ID is copied from directory; otherwise, new file’s group ID is set to effective group ID of process).
Using second option, inheriting directory’s group ID, assures us all files and directories created in that directory will have same group ID as directory. Group ownership of files and directories will then propagate down the hierarchy from that point.
access and faccessat Functions
When we open a file, kernel performs its access test based on effective user and group IDs. Sometimes, a process wants to test accessibility based on real user and group IDs. Useful when a process is running as someone else, using set-user-ID or set-group-ID. Even though a process might be set-user-ID to root, it might still want to very that real user can access a given file. access and faccessat functions base their test on real user and group IDs.
#include <unistd.h>
int access(const char *pathname, int mode);
int faccessat(int fd, const char *pathname, int mode, int flag);
Both return: 0 if OK, -1 on error.
mode is either value F_OK to test if file exists, or bitwise OR of any of next flags:
| Flag | Value |
|---|---|
| R_OK | test for read permission |
| W_OK | test for write permission |
| X_OK | test for execute permission |
faccessat function behaves like access when pathname argument is absolute or when fd argument has value AT_FDCWD and pathname argument is relative. Otherwise, faccessat evaluates pathname relative to open directory referenced by fd argument. flag argument can be used to change behaviour of faccessat. If AT_EACCESS flag is set, access checks are made using effective user and group IDs of calling process instead of real user and group IDs.
Example: real_user_check.c, program that checks access of a file with the real user ID and real group ID using access call.
$ ./real_user_check /etc/spwd.db
file exist
access error for /etc/spwd.db: permission denied
open error for /etc/spwd.db: permission denied
$ sudo su
# chown root real_user_check # set real_user_check ownser as root
# chmod 4755 real_user_check # set SUID
# exit
$ ./real_user_check /etc/spwd.db
file exist
access error for /etc/spwd.db: permission denied
open for reading OK
As we can see above, even with SUID, the function access uses the real user ID to check the access. In preceding example and in Chapter 8, we’ll sometimes switch to become superuser to demonstrate how something works. If you’re on multiuser system and do not have superuser permission, you won’t be able to duplicate these examples completely.
umask Function
Described the nine permission bits associated with every file, we can describe file mode creation mask associated with every process. unask function sets file mode creation mask for process and returns previous value. (One of the few function that doesn’t have error return).
#include <sys/stat.h>
mode_t umask(mode_t cmask);
Returns: previous file mode creation mask
cmask argument is formed as bitwise OR of any of nine constants from S_IRUSR, S_IWUSR, and so on. File mode creation mask used whenever process creates new file or new directory (If we remember from chapter 3 in open and creat functions, both accept mode argument that specifies new file’s access permission bits). We will see later how to create new directory. Any bits “on” in file mode creation mask are turned off in file’s mode.
Example: create_files_umask.c program that creates two files: one with umask of 0 (all permissions turned on), and one with umask that disables all group and other permission bits. If we check the umask and execute the program we get the next information:
$ umask # check current file mode creation mask
0022
$ ./create_files_umask
$ ls -l foo bar
-rw------- 1 Fare9 Fare9 0B Feb 3 20:37 bar
-rw-rw-rw- 1 Fare9 Fare9 0B Feb 3 20:37 foo
Most UNIX users never deal with umask value. They use the one set on login by shell’s start-up file. When writing programs that create new files, if we want to ensure specific access permission bits are enabled, we must modify umask value while process is running. Example, if we want to ensure that anyone can read a file, we should set umask to 0. Otherwise, umask value is the one from system when process started. We used shell’s umask command to print file mode creation mask before we run program and after it completes. Changing file mode creation mask of a process doesn’t affect mask of parent. All shells have a built-in umask command to set or print current file mode creation mask. Users can set umask value to control default permissions on files they create. Value is expressed in octal, one bit representing one permission to be masked off. Permission can be denied setting corresponding bits. Some common umask values are 002 (prevent others from writing our files, or 022 prevent group members and others writing our files.
Mask bit Meaning
0400 user-read
0200 user-write
0100 user-execute
0040 group-read
0020 group-write
0010 group-execute
0004 other-read
0002 other-write
0001 other-execute
Single UNIX specification requires that umask command support symbolic mode of operation. Unlike octal formta, symbolic format specifies permission are to be allowed (clear in file creation mask) instead of which one are to be denied (set in file creation mask). Check both forms below:
$ umask # print current file mode creation mask
002
$ umask -S # print symbolic form
u=rwx,g=rwx,o=rx
$ umask 027 # change file mode creation mask
$ umask -S
u=rwx,g=rx,o=
chmod, fchmod and fchmodat Functions
these functions allow us to change file access permissions for existing file.
# include <sys/stat.h>
int chmod (const char *pathname, mode_t mode);
int fchmod (int fd, mode_t mode);
int fchmodat (int fd, const char *pathname, mode_t mode, int flag);
return: 0 if OK, -1 on error
chmod operates on specified file, and fchmod operates on file already opened. fchmodat behaves like chmod when pathname argument is absolute or when fd argument has value AT_FDCWD and pathname argument is relative. Otherwise, fchmodat evaluates pathname relative to open directory referenced by fd argument. flag argument can be used to change behaviour of fchmodat (when AT_SYMLINK_NOFOLLOW flag is set, chmodat doesn’t follow symbolic links). To change permission bits of file, effective user ID of process must be equal to owner ID of file, or process must have superuser permissions. mode is specified as bitwise OR of constants:
| mode | Description |
|---|---|
| S_ISUID | set-user-ID on execution |
| S_ISGID | set-group-ID on execution |
| S_ISVTX | saved-text (sticky bit) |
| S_IRWXU | read, write, and execute by user (owner) |
| S_IRUSR | read by user (owner) |
| S_IWUSR | write by user (owner) |
| S_IXUSR | execute by user (owner) |
| S_IRWXG | read, write, and execute by group |
| S_IRGRP | read by group |
| S_IWGRP | write by group |
| S_IXGRP | execute by group |
| S_IRWXO | read, write, and execute by others |
| S_IROTH | read by others |
| S_IWOTH | write by others |
| S_IXOTH | execute by others |
These are the same bits that we explained previously but we’ve added the S_ISUID and S_ISGID, the S_ISVTX and the combination of the three permissions S_IRWXU, S_IRWXG, S_IRWXO.
Example: change_file_permissions.c In this file we will modify “bar” file previously created permissions (-rw——) for new one (rw-r–r–).
So if we check files and execute:
$ ls -lah bar foo
-rw------- 1 Fare9 Fare9 0B Feb 3 20:37 bar
-rw-rw-rw- 1 Fare9 Fare9 0B Feb 3 20:37 foo
$ ./change_file_permissions
$ ls -lah bar foo
-rw-r--r-- 1 Fare9 Fare9 0B Feb 3 20:37 bar
-rw-rwSrw- 1 Fare9 Fare9 0B Feb 3 20:37 foo
So as we can see, we’ve modified permissions for “bar” and for foo we’ve modified files adding set-group-ID permission from previous mask of permission.
Note that time and date listed by “ls” command didn’t change after program execution. chmod function updates only time that i-node was last changed. By default, ls -l lists time when contents of file were last modified (note difference between i-node time last modified and file content last modified).
chmod functions clear two of permission bits under following conditions:
- On systems, suck as Solares, if we try to set sticky bit (S_ISVTX) on regular file and do not have superuser privileges, sticky bit in mode is automatically turned off. To prevent malicious users from setting sticky bit and affecting system performance, only superuser can set sticky bit of regular file.
- Group ID of newly created file might potentially be a group that the calling process does not belong to. It’s possible for group ID of new file to be group ID of parent directory. If the group ID of new file does not equal either the effective group ID of the process or one of the process’s supplementary group IDs and if process does not have superuser privileges, then set-group-ID bit is automatically turned off. Prevents user from creating a set-group-ID file owned by group that user doesn’t belong to.
Sticky bit
Versions of UNIX System that predated demand paging, bit was known as sticky bit. If it was set for executable program file, first time program was executed, copy of program’s text was saved in swap area when process terminated (code part). Program would then load into memory more quickly next time it was executed, because swap area was handled as contiguous file. Sticky bit was set for common application programs (text editor and passes of C compiler). Right now this bit is not necessary with virtual memory and faster file system. On contemporary systems, use of sticky bit has been extended. Single UNIX Specification allows sticky bit to be set for directory. If bit is set for directory, file in directory can be removed or renamed only if user has write permission for directory and meets one of following criteria:
- Owns the file
- Owns the directory
- Is the superuser /tmp and /var/tmp are candidates for sticky bit (directories in which any user can typically create files). Permissions for these two directories are often read, write, and execute for everyone. But users should not be able to delete or rename files owned by others. (Latest versions of UNIX System referred this as saved-text bit).
chown, fchown, fchownat and lchown Functions
functions allow us to change a file’s user ID and group ID, but if either of arguments owner or group is -1, corresponding ID is left unchanged.
#include <unistd.h>
int chown(const char *pathname, uid_t owner, gid_t group);
int fchown(int fd, uid_t owner, gid_t group);
int fchownat(int fd, const char *pathname, uid_t owner, gid_t group, int flag);
int lchown(const char *pathname, uid_t owner, gid_t group);
return: 0 if OK, -1 ok error
Four functions operate similar unless referenced file is a symbolic link. That case, lchown and fchownat (with AT_SYMLINK_NOFOLLOW flag set) change owners of symbolic link itself, not file pointed to by symbolic link. fchown changes ownership of open file referenced by fd argument. Since it operates on file already open, it can’t be used to change ownership of symbolic link. fchownat behaves like chown or lchown when pathname argument is absolute or when fd argument has value AT_FDCWD and pathname argument is relative. Then if flag is AT_SYMLINK_NOFOLLOW it will act as lchown and as chown other case. Historically BSD-based systems enforced restriction that only superuser can change ownership of a file. System V however, has allowed all users to change ownership of any files they own.
We can check constant _POSIX_CHOWN_RESTRICTED, so if the constant is in effect for specified file:
- Only superuser process can change user ID of file.
- Nonsuperuser process can change group ID of file if process owns the file (effective user ID equals user ID of file), owner is specified as -1 or equals user ID of file, and group equals either effective group ID of process or one of process’s supplementary group IDs.
File Size
st_size member of stat structure contains size of file in bytes. Field is meaningful only for regular files, directories and symbolic links. For a regular file, file size of 0 is allowed. We’ll get an end-of-file indication on first read of file. For a directory, file size is multiple of a number, such as 16 or 512 (we’ll see it). For symbolic link, file size is number of bytes in filename (symbolic link contains path to file, also symbolic links do not contain normal C null byte at the end of name). Most contemporary UNIX systems provide fields st_blksize and st_blocks. First is preferred block size for I/O for file, and latter is actual number of 512-byte blocks allocated. Remember from chapter 3 that we encountered minimum amount of time required to read file when we used st_blksize for read operations. Standard I/O library (chapter 5), also tries to read or write st_blksize bytes at a time.
- Holes in a file Regular file can contain “holes”. Holes are creted by seeking past the current end of file and writing some data. read function returns data bytes of 0 for any byte positions that have not been written. If we execute “wc -c” in a file with holes, we will receive all characters read (counting holes too). That’s the size “ls -l” give us too. But if we execute “du -s” in that file, we will receive the number of 512-byte blocks (less than size of file).
But if we create a copy using “cat file > file_copy”, holes will be copied as null bytes, “ls -l” will return same size for both, but “du -s” will return a bigger number of blocks for the copy version will be bigger.
File Truncation
We would like to truncate file by chopping off data at the end of file. Emptying a file, which we can do with O_TRUNC flag to open, is special case of truncation.
#include <unistd.h>
int truncate(const char *pathname, off_t length);
int ftruncate(int fd, off_t length);
0 if OK, -1 on error
Both truncate existing file to length bytes. If previous size was greater than length, data beyond length is no longer accessible. If previous size was less than length, file size will increase and data between old end of file and newer will read as 0 (hole is probably created in the file). ftruncate is used when we need to empty a file after obtaining a lock on the file.
File Systems
Appreciate concept of links to file, we need understanding of the structure of UNIX file system. Understanding difference between i-node and directory entry that points to i-node is also useful.
Various UNIX implementations are in use today. Solaris, supports several types of disk file systems: BSD-derived UNIX file system (UFS), PCFS to read and write DOS-formatted diskettes, and HSFS to read CD file systems. UFS is based on Berkeley fast file system.
Each file system type has own characteristics features-some can be confusing. Most UNIX file systems support case-sensitive filenames. Mac OS X, however, the HFS file system is case-preserving with case-insensitive comparisons. So file.txt and file.TXT would be the same, one would overwrite the other. However, only the name used when the file was created is stored in file system (case-preserving aspect). Any permutation of upper and lowercase in “file.txt” characters will match searching for the file.
We can think of a disk drive being divided into one or more partitions. Each partition can contain a file system (Figure 4.13). And i-nodes are fixed-length entries that contain most of information about a file.
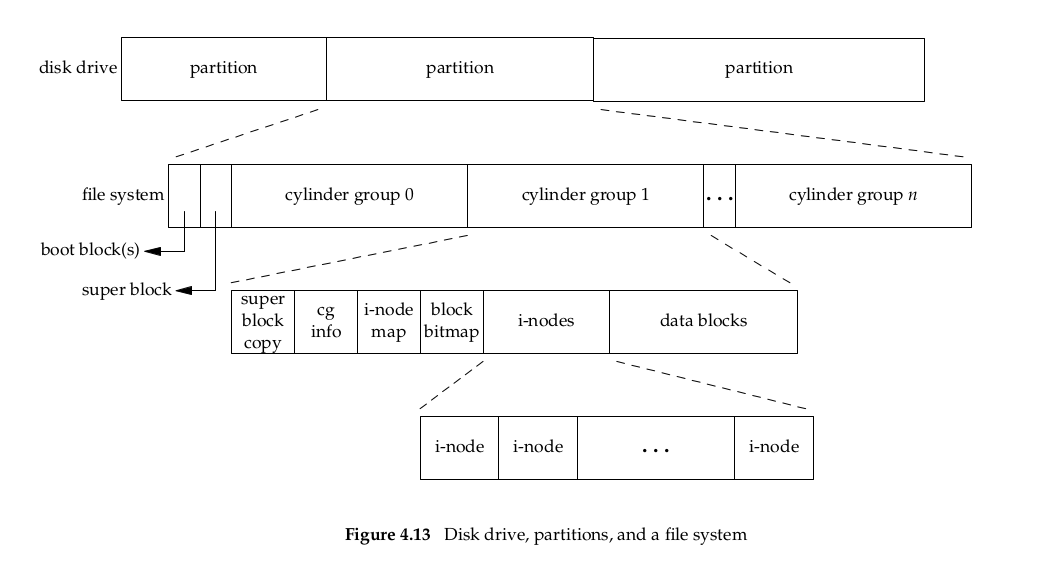
Now if we examine i-node and data block portion of cylinder group in more detail, we have the next from Figure 4.14:
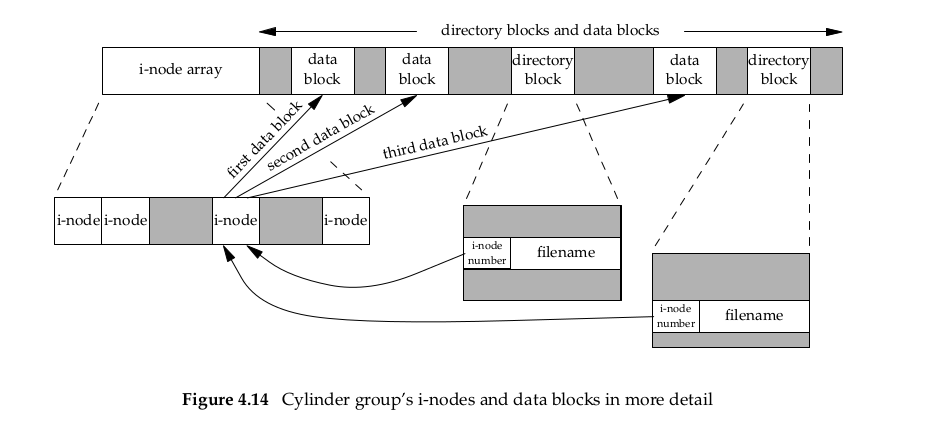
Note following points:
- Two directory entries point to same i-node entry. Every i-node has link count that contains number of directory entries that point to it. Only when link count goes to 0 can the file be deleted (releasing data blocks of the file that are pointed by i-node). This is why operation of “unlinking a file” does not always mean “deleting the blocks associated with file”. This is why function that removes a directory entry is called unlink, not delete. In stat structure, link count is contained in st_nlink member. Its primitive system data type is nlink_t. These types of links are called hard links, from Section 2.5.2 POSIX.1 constant LINK_MAX specifies maximum value for file’s link count.
- Other type of link symbolic link. With a symbolic link, actual contents of file (data blocks) store name of the file that symbolic link points to. We can see some example with ls command, example filename in directory entry is string “lib” and the 7 bytes of data in file are usr/lib:
lrwxrwxrwx 1 root 7 Sep 25 07:14 lib -> usr/lib
-
i-node contains all information about file: file type, file’s access permissino bits, size of file, pointers to file’s data blocks, etc. Most stat structure information is obtained from i-node. Only two items of interest are stored in directory entry: filename and i-node number (identifier in i-node array). Other items (length of filename and length of directory record) are not of interest. Data type for i-node number is ino_t.
- Because i-node number in directory entry points to an i-node in same file system, a directory entry can’t refer to an i-node in different file system. This is why ln command can’t cross file systems. We’ll see it.
- Renaming a file without changing file systems, actual contents of file need not be moved, all that needs is to add new directory entry that points to existing i-node and then unlink old directory entry. Link count will remain the same. Example, renaming file /usr/lib/foo to /usr/foo, contents of file foo need not be moved if directories /usr/lib and /usr are on same file system. This is how mv command operates (for that reason cut-paste is faster than copying between same file system).
We’ve talked about concept of link count for regular file, but what about count field for a directory? Create new directory in working directory:
mkdir testdir
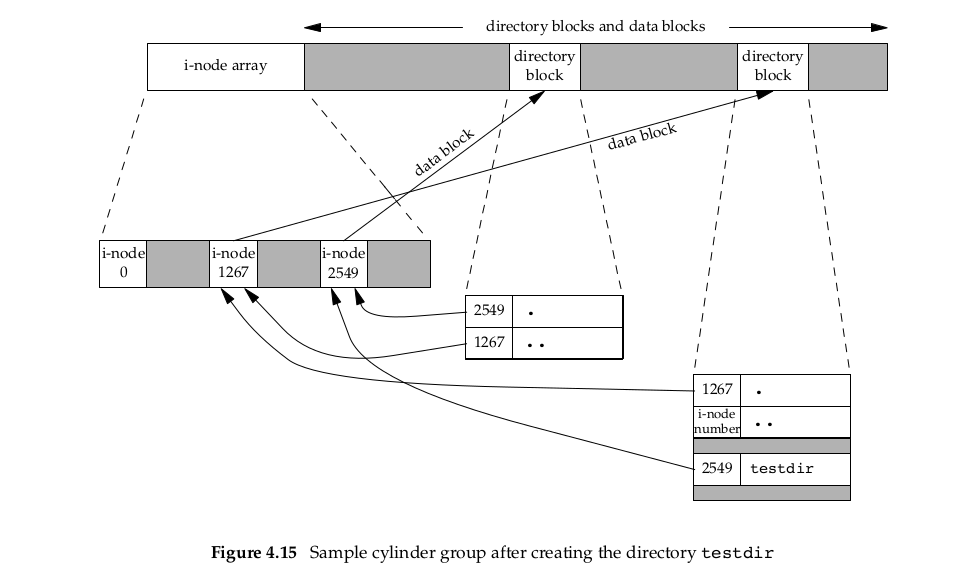
i-node whose number is 2549 has a type field “directory” and a link count equal to 2 (as it is referenced in directory with i-node 1267 and in itself). Any leaf directory (directory that does not contain any other directories) always has a link count of 2 directory entry that names directory (testdir) and entry for dot (‘.’) in that directory. Directory with i-node number 1267 has a type field of “directory” and a link count greater than or equals to 3. As it is refereneced in itself (dot), in parent directory that gives its name (not showed in image) and from testdir dot-dot directory. Every subdirectory in parent directory causes parent directory’s link count to be increased by 1. Format is similar to classic format of UNIX file system (there are many references about this).
link, linkat, unlink, unlinkat, and remove Functions
A file can have multiple directory entries pointing to its i-node. We can use link or linkat to create a link to existing file.
#include <unistd.h>
int link (const char *existingpath, const char *newpath);
int linkat(int efd, const char *existingpath, int nfd, const char *newpath, int flag);
Both return: 0 if OK, -1 on error
Functions create new directory entry, newpath, that references existing file existingpath. If newpath exists, error is returned. Only name of newpath is created. Rest of path must already exist.
With linkat function, existing file is specified by efd and existingpath, and new pathname is specified by nfd and newpath. If either pathname is relative, it is evaluated relative to corresponding file descriptor. If either file descriptor is set to AT_FDCWD, then pathname, if it’s relative, is evaluated relative to current directory. If either pathname is absolute, file descriptor is ignored.
When existing file is symbolic link, flag argument of linkat is used to control if link to symbolic link or to file which symbolic link points is created. If AT_SYMLINK_FOLLOW flag is set in flag, link is created to target of symbolic link, otherwise link to symbolic link is created.
Creation of new directory entry and increment of link count must be atomic operation.
Most implementations require both pathnames be on same file system, although POSIX.1 allows implementation to support linking across file systems. If implementation supports creation of hard links to directories, it is restricted to only superuser. Constraint exists because such hard links can cause loops in file system, which most utilities that process file system aren’t capable of handling. Many file system implementations disallow hard links to directories for this reason.
To remove existing directory entry, we call unlink:
#include <unistd.h>
int unlink(const char *pathname);
int unlinkat(int fd, const char *pathname, int flag);
Both return: 0 if OK, -1 on error
Functions remove directory entry and decrement link count of file referenced by pathname. If there are other links to the file, data in the file is still accessible through other links. File is not changed if an error occurs. To unlink a file, we must have WRITE permissions and EXECUTE permission in directory containing the directory entry. Also, if sticky bit is set in this directory we must have WRITE permission for the directory and meet one of following criteria:
- Own file
- Own directory
- Have superuser privileges
Only when link count reaches 0 can the contents be deleted. Other condition prevents contents of a file from being deleted: some process has file open. When a file is closed, kernel first checks count of number of processes that have file open. If count has reached 0, kernel then checks link count; if it’s 0, file’s content are deleted.
If pathname argument is relative, unlinkat function evaluates pathname relative to directory represented by fd file descriptor. If fd argument is set to AT_FDCWD, then pathname is evaluated relative to current working directory of calling process. If pathname argument is absolute pathname, then fd argument is ignored.
flag argument gives callers a way to change default behavior of unlinkat. When AT_REMOVEDIR flag is set, then unlinkat function can be used to remove a directory, similar to using rmdir. If flag is clear, unlinkat operates like unlink.
Example: unlink_tempfile.c, this program first it tries to open a temporary file called “tempfile” and if it exists, program unlinks it.
$ ls -l tempfile # look how big file is
-rw-r----- 1 sar 413265408 Jan 21 07:14 tempfile
$ df /home # check how much free space is available
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/hda4 11021440 1956332 9065108 18% /home
$ ./unlink_tempfile & # run program in the background
1364 # shell prints its process ID
$ fie unlinked # file is unlinked
ls -l tempfile # see if filename is still there
ls: tempfile: No such file or directory # directory entry is gone
$ df /home # see if space is available yet
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/hda4 11021440 1956332 9065108 18% /home
$ done # the program is done, all open files are closed
df /home # now disk space should be available
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/hda4 11021440 1552352 9469088 15% /home
$ # now the 394.1 MB of disk space are available
This property of unlink is often used by program to ensure that temporary file it creates won’t be left around in case programc rashes. Process creates a file using open or creat and then immediately calls unlink. File is not deleted, however, because it is still open. Only when process closes the file or terminates, causes kernel to close all its open files, file is deleted. If pathname is symbolic link, unlink removes symbolic link, not file referenced by link. There’s no function to remove file referenced by symbolic link given name of the link.
Superuser can call unlink with pathname specifying a directory if file system supports it, but function rmdir should be used instead to unlink a directory. We can also unlink a file or directory with remove function. For a file, remove is identical to unlink. For a directory, remove is identical to rmdir.
#include <stdio.h>
int remove (const char *pathname);
Returns: 0 if OK, -1 on error
ISO C specifies remove function to delete a file. Name was changed from historical UNIX name of unlink because most non-UNIX system that implements the C standard didn’t support the concept of links to a file at the time.
rename and renameat Functions
File or directory is renamed with either the rename or renameat function.
#include <stdio.h>
int rename (const char *oldname, const char *newname);
int renameat (int oldfd, const char *oldname, int newfd, const char *newname);
Both return: 0 if OK, -1 on error
Rename function is defined by ISO C for files (C standard doesn’t deal with directories) POSIX.1 expanded definition to include directories and symbolic links.
Several conditions to describe for these functions, depending on whether oldname refers to a file, a directory, or symbolic link. We must also describe what happens if newname already exists.
- oldname specifies file that it’s not a directory, we’re renaming a file or symbolic link. This case, if newname exists, it cannot refer to directory. If newname exists and is not a directory, it is removed, and oldname is renamed. We must have write permission for directory containing oldname and directory containing newname, since we change both directories.
- oldname specifies a directory. If newname exists, it must refer to a directory, and must be empty (it contains only dot and dot-dot). If newname is an empty directory, it’s removed, and oldname renamed. Additionally, when we rename a directory, newname cannot contain as a path prefix oldname. Example, we can’t rename /usr/foo to /usr/foo/testdir, as foo cannot be removed to create new path.
- If oldname or newname refers to symbolic link, link itself is processed, not file to which it resolves.
- We can’t rename dot or dot-dot. Neither dot nor dot-dot can appear as last component of oldname or newname.
- Special case, if oldname and newname refer to same file, function returns successfully without changing anything (it would be stupid to process it).
Probably if newname exists and as we’re removing a directory entry where oldname is, we need write permission and execute permission in the directory containing oldname and in the directory containing newname.
renameat function, same functionality as rename function, except when oldname or newname refers to relative pathname. If oldname specifies relative pathname, it is evaluated relative to directory referenced by oldfd. Same as newname if it’s relative, it is evaluated relative to directory referenced by newfd. oldfd or newfd (or both) can be set to AT_FDCWD to evaluate corresponding pathname relative to current directory.
Symbolic Links
Indirect pointer to a file, unlike hard links, which pointed directly to i-node of the file. Symbolic links were introduced to get around limitations of hard links.
- Hard links require link and file reside in same file system (normally).
- Only superuser can create hard link to a directory (when supported by underlying file system).
No file system limitations on symbolic link and what it points, anyone can create a symbolic link to a directory. Symbolic links typically used to “move” a file or entire directory hierarchy to another location on a system. Using functions that refer to a file by name, we need to know whether function follows symbolic link. If function follows symbolic link, pathname argument to function refers to file pointed to by symbolic link. Otherwise, pathname argument refers to link itself, not file pointed. Next lists says which functions described in the chapter follow a symbolic link. Function mkdir, mkfifo, mknod and rmdir do not appear, as they return error when pathname is symbolic link. Also functions that take a file descriptor argument, such as fstat and fchmod, are not listed, as functions use a file descriptor commonly returned by a function which handles symbolic link. (Historically chown didn’t follow symbolic links, but now does).
- Follows Symbolic link: access, chdir, chmod, chown, creat, exec, link, open, opendir, pathconf, stat, truncate.
- Does not follow symbolic link: lchown, lstat, readlink, remove, rename, unlink.
One exception to behavior of the lists, when open is called with O_CREAT and O_EXCL. In this case, if pathname refers to symbolic link, open will fail with errno set to EEXIST. Behavior is intented to close a security hole so privileged processes can’t be fooled into writing to wrong files.
Example
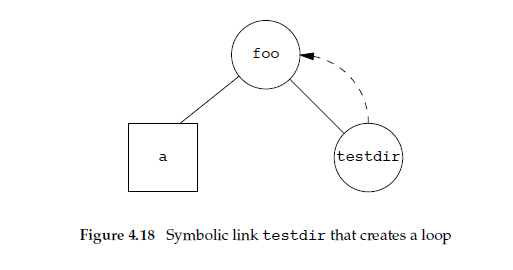
It is possible to introduce loops into file system using symbolic links. Most functions that look up a pathname return errno of ELOOP when this occurs. Consider following commands:
$ mkdir foo # make new directory
$ touch foo/a # create 0-length file
$ cd foo
$ ln -s ../foo foo/testdir # create a symbolic link
$ ls -l foo
total 0
-rw-r----- 1 sar 0 Jan 22 00:16 a
lrwxrwxrwx 1 sar 6 Jan 22 00:16 testdir -> ../foo
This creates a directory foo that contains file a and a symbolic link that points to foo. Figure 4.18 shows hierarchy, drawing directory as circle and file as square.
If we use standard function ftw on Solaris to descend through file hierarchy, printing each pathname encontered, we would have as output:
foo
foo/a
foo/testdir
foo/testdir/a
foo/testdir/testdir
foo/testdir/testdir/a
foo/testdir/testdir/testdir
foo/testdir/testdir/testdir/a
(many more lines until an ELOOP error)
We will see later, our own version of ftw that uses lstat instead of stat to prevent following symbolic links. (On Linux, ftw and nftw function records all directories seen and avoid processing a directory more than once, so they don’t display this behavior).
Loop of this form is easy to remove. We can unlink file foo/testdir as unlink does not follow symbolic link. But if we create hard link that forms loop of this type, removal is much more difficult. This is why link function will not form a hard link to a directory unless process has superuser privileges.
When we open a file, if pathname passed to open specifies a symbolic link, open follows link to specified file. If file pointed to by symbolic link doesn’t exist, open returns error saying it can’t open the file.
$ ln -s /no/such/file myfile # create symbolic link
$ ls myfile
myfile # symbolic link exists
$ cat myfile # try read file pointed
cat: myfile: No such file or directory
$ ls -l myfile # try -l option
lrwxrwxrwx 1 sar 13 Jan 22 00:26 myfile -> /no/such/file
File myfile exists, but cat says there is no such file, because myfile is a symbolic link, cat uses open and file pointed to by symbolic link doesn’t exist. The -l option to ls gives us two hints: first character is an l, which means symbolic link, and sequence -> also indicates a symbolic link. ls command has another option (-F) that appends an at-sign(@) to filenames that are symbolic links, which can help us spot symbolic links in directory listing without -l option.
Creating and Reading Symbolic Links
To do this next functions are used:
#include <unistd.h>
int symlink(const char *actualpath, const char *sympath);
int symlinkat(const char *actualpath, int fd, const char *sympath);
Both return: 0 if OK, -1 on error
New directory entry sympath created that points to actualpath. It’s not required that actualpath exist when symbolic link is created. Also, actualpath and sympath need not to reside in same file system.
symlinkat function is similar to symlink, but sympath argument is evaluated relative to directory referenced by open file descriptor for that directory (specified by fd argument). If sympath argument specifies absolute pathname, or if fd argument has special value AT_FDCWD, symlinkat behaves same way as symlink.
Because open function follows a symbolic link, we need a way to open link itself and read name in link. readlink and readlinkat functions do this.
#include <unistd.h>
ssize_t readlink(const char* restrict pathname, char *restrict buf, size_t
bufsize);
ssize_t readlinkat(int fd, const char* restrict pathname,
char *restrict buf, size_t bufsize);
Both return: number of bytes read if OK, -1 on error
Functions combine action of open, read and close. If successful, they return number of bytes placed into buf. Contents of symbolic link returned in buf are not null terminated. readlinkat function behaves same way as readlink function when pathname argument specifies absolute pathname, or when fd argument has special value AT_FDCWD. However, when fd argument is valid file descriptor of an open directory and pathname argument is relative pathname, readlinkat evaluates pathname relative to open directory fd.
File Times
We saw how 2008 version of Single UNIX Specification increased resolution of the time fields in stat structure from seconds to seconds plus nanoseconds. Actual resolution stored with each file’s attributes depends on file system implementation. For file systems that store timestamps in second, nanoseconds fields will be filled with zeros. For file systems that store timestamps in a resolution higher than seconds, partial seconds value will be converted into nanoseconds and returned in nanoseconds fields. Three time fields are maintained for each file
| Field | Description | Example | ls(1) option |
|---|---|---|---|
| st_atim | last-access time of file data | read | -u |
| st_mtim | last-modification time of file data | write | default |
| st_ctim | last-change time of i-node status | chmod, chown | -c |
Note difference between modification time (st_mtim) and changed status time (st_ctim). Modification time indicates when contents of file were last modified. Changed-status time indicates when the i-node of file was last modified. We’ve covered many operations that affect the i-node without changing actual contents of the file: changing file access permissions, changing user ID, changing number of links, and so on. Information of the i-node is stored separately from actual contents of file, we need changed-status time, in addition to modification time. System does not maintain last-access time for an i-node. This is why functions access and stat, don’t change any of three times. The access time is used by system administrators to delete files that have not been accessed for certain amount of time. For example files a.out or core not accessed in past week. find command oftend used for this type of operation. The ls displays or sorts only on one of three time values. By default, when invoked with -l or -t option, it uses modification time of a file. The -u shows the access time, and -c option shows the changed-status time. Next figure shows functions from this section, recall that a directory is simply a file containing directory entries: filenames and associated i-node numbers. Adding, deleting, or modifying directory entries can affect the three times associated with that directory. So for that reason next table contains one column for three times associated with file or directory, and other column for three times associated with parent directory of referenced file or directory. Example: creating new file affects directory that contains new file, and it affects i-node for new file. Reading or writing a file, affects only i-node of file and has no effect on directory.
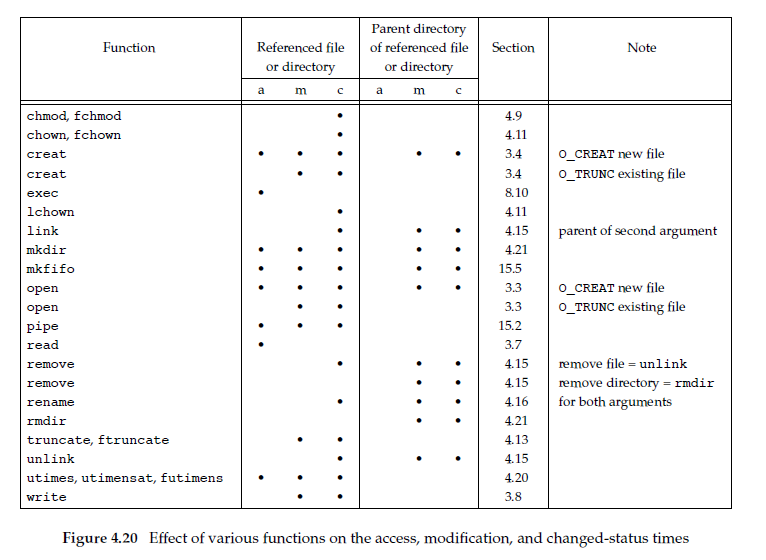
futimens, utimensat, and utimes Functions
Several functions available to change access time and the modification time of a file. futimens and utimensat provide nanosecond granularity for timestamps, using timespec structure (same structure used by stat family).
#include <sys/stat.h>
int futimens(int fd, const struct timespec times[2]);
int utimensat(int fd, const char *path, const struct timespec times[2],
int flag);
Both return: 0 if OK, -1 on error
In both, first element of times array argument contains access time, and the second element contains the modification time. The two time values are calendar times, which count seconds since Epoch. Partial seconds are expressed in nanoseconds.
Timestamps can be specified in one of four ways:
- times argument is null pointer. This case, both timestamps are set to current time.
- times argument points to an array of two timespec structures. If tv_nsec field has special value UTIME_NOW, corresponding timestamp is set to current time. Corresponding tv_sec field is ignored.
- times argument points to array of two timespec structures. If either tv_nsec field has special value UTIME_OMIT, then timestamp is unchanged. Corresponding tv_sec field is ignored.
- times argument points to an array of two timespec structures and tv_nsec contains a value other than UTIME_NOW or UTIME_OMIT. In this case, corresponding timestamp is set to value specified by corresponding tv_sec and tv_nsec fields.
Necessary privileges depend on value of times argument.
- If times is a null pointer or if either tv_nsec is set to UTIME_NOW, the effective user ID of process must equal the owner ID of the file, process must have write permission for file, or process must be a superuser process.
- If times is non-null pointer and either tv_nsec has a value other than UTIME_NOW or UTIME_OMIT, effective user ID of process must equal the owner ID of the file, or process must be superuser process. Merely having write permission for the file is not adequate.
- If times is non-null pointer and both tv_nsec fields are set to UTIME_OMIT, no permissions checks are performed.
With futimens you need to open file to change its times. utimensat provides a way to change file’s times using file’s name. pathname argument is evaluated relative to fd argument, which is either a file descriptor of an open directory or special value AT_FDCWD to force evaluation relative to current directory of calling process. If pathname is an absolute pathname, fd argument is ignored.
flag argument to utimensat can be sued to further modify default behavior. If AT_SYMLINK_NOFOLLOW flag is set, then times of symbolic link itself are changed (if pathname refers to a symbolic link). Default behavior is to follow a symbolic link and modify times of file which link refers.
futimens and utimensat are included in POSIX.1. Third function, utimes is included in Single UNIX Specification as part of XSI option.
#include <sys/time.h>
int utimes(const char *pathname, const struct timeval times[2]);
Returns: 0 if OK, -1 on error
utimes function operates no pathname, times argument is a pointer to an array of two timestamps -acces time and modification time- but they are in seconds and microseconds:
struct timeval
{
time_t tv_sec; /* seconds */
long tv_usec; /* microseconds */
}
We are unable to specify av alue for changed-status time, st_ctim -time the i-node was last canged- this file is automatically updated when utime function is called. On some versions of UNIX System, touch command, uses one of these functions. Also tar and cpio optionally call these functions to set a file’s times to time values saved when file was archived.
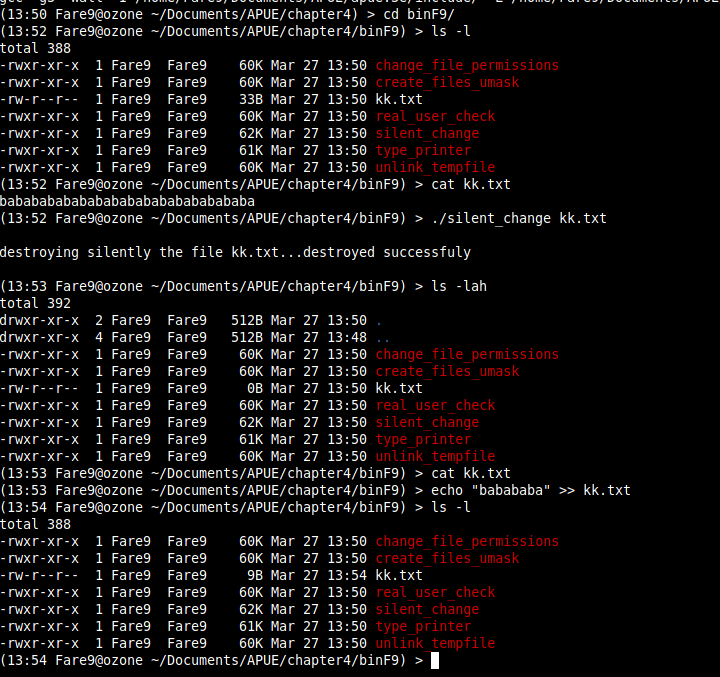
Example: silent_change.c this file truncate files to zero length using O_TRUNC option of open but does not change access time or modification time. To do this, program first obtains times with stat function, truncated the file, then resets times with futimens function.
The example can be seen in next image:
mkdir, mkdirat, and rmdir Functions
Directories created with mkdir and mkdirat, deleted with rmdir.
#include <sys/stat.h>
int mkdir(const char *pathname, mode_t mode);
int mkdirat(int fd, const char *pathname, mode_t mode);
Both return: 0 ij OK, -1 on error
Used to create a new empty directory. Entries for dot and dot-dot are created automatically. Specified file access permissions mode are modified by file mode creation mask of the process. Common mistake specify same mode as for a file: read and write permissions only. For a directory, we normally want at least one of the execute bits enabled, to allow access to filenames within directory (for directory listing at least) (Check previous exercises).
UserID and groupID of new directory are established according to rules described in section Ownership of New Files and Directories.
The mkdirat function similar to mkdir function. When fd argument has special value AT_FDCWD, or when pathname specifies absolute pathname, mkdirat behaves exactly like mkdir. Otherwise, fd argument is an open directory from which relative pathnames will be evaluated.
An empty directory is deleted with rmdir. An empty directory is one that contains only entries for dot and dot-dot.
#include <unistd.h>
int rmdir(const char *pathname);
Returns: 0 if OK, -1 on error
If link count of directory becomes 0 with this call, and if no other process has directory open, space occupied by directory is freed. If one or more processes have the directory open when the link count reaches 0, last link is removed, and dot and dot-dot entries are removed before this function returns. Additionally, no new files can be created in the directory. The directory is not freed, until last process closes it.
Reading Directories
Directories can be read by anyone who has access permission to read directory. But only kernel can write to a directory, to preserve file system sanity. Recall from section File Access Permission that write permission bits and execute permission bits for a directory determine if we can create new files in directory and remove files from directory (it doesn’t mean if we can write to directory itself). Actual format of a directory depends on UNIX System implementation and the design of the file system. Version 7 had a simple structure: each directory entry was 16 bytes, 14 for filename and 2 for i-node number. When longer filenames were added to 4.2BSD, each entry became variable length, which means that any program that reads a directory is now system dependent. To simplify process of reading a directory, a set of directory routines were developed and are part of POSIX.1 Many implementations prevent applications from using read function to access the contents of directories, thereby further isolating applications from implementation-specific details of directory format. As these structures manage strings and variable data sizes, it’s necessary to use the standard functions in order to read strings from directory entries correctly, also avoid memory leakages, and so on.
#include <dirent.h>
DIR *opendir(const char *pathname);
DIR *fdopendir(int fd);
Both return: pointer if OK, NULL on error
struct dirent *readdir(DIR *dp);
Returns: pointer if OK, NULL at end of directory or error
void rewinddir(DIR *dp);
int closedir(DIR *dp);
Returns: 0 if OK, -1 on error
long telldir(DIR *dp);
Returns: current location in directory associated with dp
void seekdir(DIR *dp, long loc);
The fdopendir function first appeared in version 4 of Single UNIX Specification. It provides a way to convert an open file descriptor into a DIR structure for use by directory handling functions.
telldir and seekdir are not part of the base POSIX.1 standard. They are included in XSI option in Single UNIX Specification, so all conforming UNIX System implementations are expected to provide them.
The dirent structure defined in *
ino_t d_ino; /* i-node number */
char d_name[]; /* null-terminated filename */
d_ino entry is not defined by POSIX.1, because it is an implementation feature, but it is defined as part of XSI option in POSIX.1. POSIX.1 only defines d_name.
Size of D_name entry isn’t specified, but it is guaranteed to hold at least NAME_MAX characters, not including terminating null byte. Since filename is null terminated, it doesn’t matter how d_name is defined in header, because array size doesn’t indicate length of filename. The DIR structure is an internal structure used by seven functions to maintain information about directory being read. Purpose of DIR is similar to the one of FILE maintained by standard I/O library, described in next chapter. Pointer to DIR structure returned by opendir and fdopendir is used with other five functions. The opendir function initializes things so first readdir returns first entry in the directory. When DIR structure is created by fdopendir, first entry returned by readdir depends on file offset associated with file descriptor passed to fdopendir. Ordering of entries within the directory is implementation dependent, and not usually alphabetical.
Example: path_traverser.c this program traverses a file hierarchy. Goal is to produce a count of various types of files shown in Figure 4.4. The program takes a single argument, the starting pathname, and recursively descends hierarchy from that point. Solaris for this provide the function ftw that performs actual traversal, but it follows the symbolic links because it uses stat so some files are counted twice, as a fix, Solaris provides an additional function nftw. Instead of using this tool, we will write our own.
chdir, fchdir, and getcwd Functions
Every process has current working directory. Directory is where search for all relative pathnames start. When a user logs in to a UNIX system, current working directory normally start at directory specified by sixth field in /etc/passwd file (user’s home directory). Current working directory is an attribute of a process; home directory is an attribute of a login name. We can change current working directory of calling process calling chdir of fchdir:
#include <unistd.h>
int chdir(const char* pathname);
int fchdir(int fd);
Both return: 0 if OK, -1 on error
We can specify current working directory as a pathname or an open file descriptor.
Example: change_chdir.c Because it’s an attribute of process, current working directory cannot affec processes tha invoke process that executes chdir. So the program written in here, it doesn’t change at all any current directory for shell. So if we execute it:
$ pwd
/usr/lib
$ ./change_chdir
chdir to /tmp succeeded
$ pwd
/usr/lib
Current working directory for the shell didn’t change. This is a side effect of the way that shell executes programs. Each program is run in separate process, so current working directory of the shell is unaffected by call to chdir in the program. For this reason, chdir function has to be called directly from the shell, so cd command is built into the shells (IMPORTANT!!!).
Because kernel must maintain knowledge of current working directory, we should be able to fetch its current value. Kernel doesn’t maintain full pathname of directory. Instead, kernel keeps information about directory, such as a pointer to directory’s v-node. (Linux kernel can determine full pathname. Its components are distributed throughout mount table and dcache table, and are reassembled, example, when you read /proc/self/cwd symbolic link). What we need is a function that starts at current working directory (dot) and works its way up directory hierarchy, using dot-dot to move up one level. At each level reads directory entries until it find name that corresponds to i-node at directory that it just came from. Repeating process until root is found. We have a function that do this for us:
#include <unistd.h>
char *getcwd(char *buf, size_t size);
Returns: buf if OK, NULL on error
We pass to the function address of a buffer buf and its size (in bytes). Buffer must be large enough to accommodate absolute pathname plus a terminating null byte, or else an error will be returning. (Some older implementations of getcwd allow first argument buf to be NULL, so function calls malloc to allocate size number of bytes dynamically. This is not POSIX.1 or Single UNIX Specification should be avoided).
Example: get_current_dir.c this program changes to a specific directory and then calls getcwd to print working directory.
In case of trying chdir follows symbolic link, but getcwd has no idea so it does not return symbolic link it returns the real path.
getcwd function useful when we have an application that needs to return location in file system where it started out. We can save starting location by calling getcwd before we change working directory. After we complete processing, we can pass pathname obtained to chdir to return to our starting location in file system. fchdir function proces us with easy way to accomplish this task. Instead of calling getcwd, we can open current directory and save file descriptor before we change to a different location in file system.
Device Special Files
Two fields st_dev and st_rdev are often confused. We’ll use these in chapter 18 when we write ttyname function. Rules for their use are simple:
- Every file system known by its major and minor device numbers, encoded in primitive system data type dev_t. Major number identifies device driver and sometimes encodes which peripheral board to communicate with; minor number identifies specific subdevice. Figure 4.13 a disk drive often contains several file systems. Each file system on same disk drive would usually have same major number, but different minor number.
- We can access major and minor device numbers through two macros defined by most implementations: major and minor. We don’t care how the two numbers are stored in a dev_t object. (POSIX.1 states that the dev_t type exists, but doesn’t define what it contains or how to get at its contents. The macros major and minor are defined by most implementations. Which header they are defined in depends on the system. They can be found in <sys/types.h> on BSD-based systems. Solaris defines their function prototypes in <sys/mkdev.h>, because the macro definitions in <sys/sysmacros.h> are considered obsolete in Solaris. Linux defines these macros in <sys/sysmacros.h>, which is included by <sys/types.h>.)
- st_dev value for every filename on a system is device number of file system containing filename and its corresponding i-node.
- Only character special files and block special files have a st_rdev value. Value contains device number for actual device.
Example: print_special_file.c (from the book, didn’t compile because of major and minor functions)
#include "apue.h"
#ifdef SOLARIS
#include <sys/mkdev.h>
# endif
int
main(int argc, char * argv[]) {
int i;
struct stat buf;
for (i = 1; i < argc; i++) {
printf("%s: ", argv[i]);
if (stat(argv[i], & buf) < 0) {
err_ret("stat error");
continue;
}
printf("dev = %d/%d", major(buf.st_dev), minor(buf.st_dev));
if (S_ISCHR(buf.st_mode) || S_ISBLK(buf.st_mode)) {
printf(" (%s) rdev = %d/%d",
(S_ISCHR(buf.st_mode)) ? "character" : "block",
major(buf.st_rdev), minor(buf.st_rdev));
}
printf("\n");
}
exit(0);
}
Summary of File Access Permission Bits
We’ve covered all file access permission bits, some of which serve multiple purposes. Next figure summarizes these permission bits, and their interpretation when applied to a regular file and a directory:
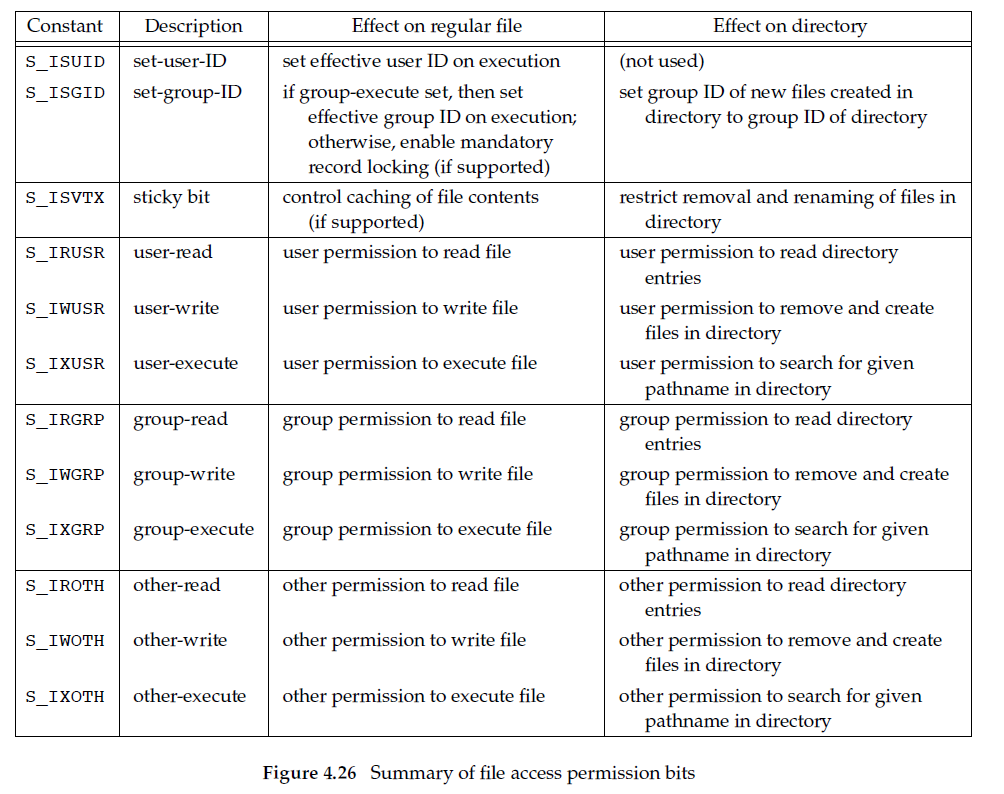
So Final nine constants can also be grouped into threes as follows:
| S_IRWXU = S_IRUSR | S_IWUSR | S_IXUSR |
| S_IRWXG = S_IRGRP | S_IWGRP | S_IXGRP |
| S_IRWXO = S_IROTH | S_IWOTH | S_IXOTH |
Summary
Chapter has centered on stat function. We’ve gone through each member in stat structure in detail. This led us to examine all the attributes of UNIX files and directories. We’ve looked at how files and directories might be laid out in a file system, and we’ve seen how to navigate the file system namespace. A thorough understanding of all properties of files and directories and all the functions that operate on them is essential to UNIX programming.