Analysis YANSOllvm
byAnalysis of YANSOllvm
This post will be a summary of a research from my analysis of the obfuscation called YANSOllvm (Yet Another Not So Obfuscated LLVM). Here I will describe the obfuscation framework, the analysis of each obfuscation provided, and so on. In any case the project is completely free and can be found in here YANSOllvm.
Description of the research
Some time ago I discovered and started to get interest on a framework called LLVM, this is a huge project which offers all the necessary libs and files to write your own compiler, or just use it as your compiler framework instead of using others as gcc (as for example playstation did with PS4). The framework separates the compilation process into 3 main steps (common steps for compilation) as a front-end, an Intermmediate-Representation(IR) and finally a back-end. The front-end will parse the source code through different analysis (lexical, syntactic and semmantic) in order to produce something called LLVM IR, LLVM has different front-ends for different source code languages, after this first step, we have LLVM IR files, these are intermmediate representations of the source code files, and are as most as possible independent from the source type and from the final machine (sadly this is not always possible). In this step different optimizations can be applied as this IR is a structured and highly typed language, differen transformations can be applied in here in order to reduce code size, loop unrolling, function inlining and so on. Finally once the LLVM IR has been optimized (or not!), a final step is followed known as back end the back end will transform the intermmediate representation to something closer to the machine as it’s the assembly language (specific from the architecture as could be x86, i64, arm, mips, powerpc; llvm supports different back ends), this assembly coded can be assembled into object files and finally linked with libraries in order to produce a working binary. Separating these three steps make easier for a framework to create compilers for any language and any architecture, so if you want to support a new language you just need to create a front end, or if you want to support a different architecture just drop a new back end, this task is not trivial but it’s easier than doing all the different steps once and again and again.
As I commented, llvm uses an intermmediate representation called LLVM IR, highly typed (commonly a pain in the ass, as you always need to do different type of castings between types) and structured. Many optimizations are applied here so, the optimizations can be applied in any compilation process using the debugging tool called opt with different flags for different optimization algorithms. In the same way you can apply optimizations you can scramble and obfuscate the code applying “deoptimizations”, different projects do this as for example (Obfuscator-LLVM)[https://github.com/obfuscator-llvm/obfuscator] or the one that here we will analyze.
This research will be useful for learning a bit more about LLVM, the deoptimization process, obfuscation with LLVM IR and the use of different tools probably.
Compiling YANSOllvm
In the (official repo)[https://github.com/emc2314/YANSOllvm] we have the next structure:
Also we have some steps to build the project:
As the README says, the project is based in LLVM version 9 (LLVM release new versions constantly and if you work with one, maybe the component you used it’s not the same in the next version), luckily LLVM version 9 it’s compilable in new versions of ubuntu as 18.04 or 20.04 (if not you probably need an older version of gcc, for example in order to compile LLVM 3.8.1 you can use gcc-4.8 in Ubuntu 18.04 as you will not find it in Ubuntu 20.04). The different folders will be merged with the llvm project. For example, the path lib/Target/X86/ will contain the different files from this part of the (repo)[https://github.com/emc2314/YANSOllvm/tree/master/lib/Target/X86]:
Or the source code of LLVM IR passes for obfuscation will be stored in lib/Transforms/Obfuscate/ in the path lib/Transforms/ you will also find other passes but this time optimizations passes provided by LLVM, also a HelloWorld pass used to learn how to write a llvm pass.
![]()
Before of following the steps provided by the repo, don’t forget to execute the python file provided in lib/Target/X86/genObfCC.py that will generate the specification (td) file ObfCall.td .
Once the compilation process has finished, we will have a bin folder with all the llvm tools:

And another one with compiled libs, where we will have the obfuscation passes library LLVMObf.so, the lib folder:

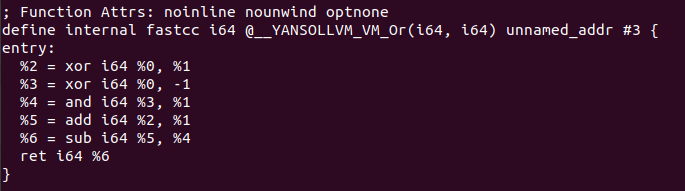
VM.cpp pass
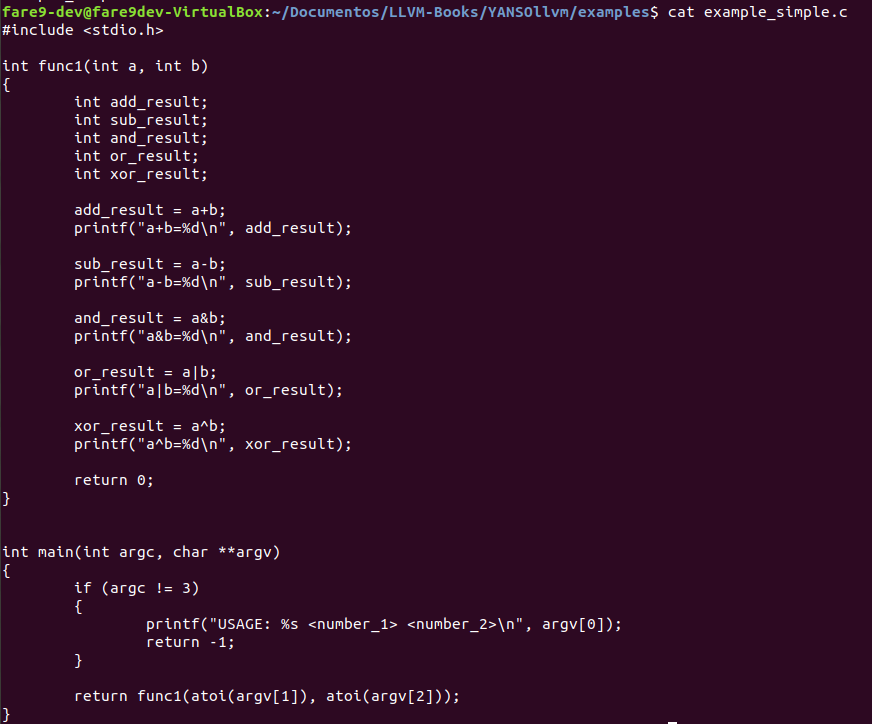
This pass of YANSOllvm will change different arithmetic and logic operations by functions which implement the same operation but in a scrambled way, so for example if you have in your code the add operation, you will have a call that implement something really simple, as some operations inside of a function and we will go watching what we have, this changes implies a syntactic change but not a semantyc one:
We will compile this with clang-9 into a binary file:

And also we will generate the bitcode (compiled LLVM IR) with clang-9 -emit-llvm:

So we have the next if we use the binary file:

Now with the optimizer tool opt from llvm we will generate the scrambled version:

Okay, let’s going to compare the two different add operation between the two bitcode files, to get the LLVM IR code from the bitcode file we will use the LLVM tool called llvm-dis:

In the left part we have the programmed version of the add operation from example_simple.c, the code starts storing the function parameters in local variables (LLVM IR follows a Static Single Assignment - SSA form property where variables are assigned only once), then thos local variables are loaded into other auxiliars two of 32 bits, then add operation is applied to those two variables (%10 and %11) and stored the result in %12. Finally %12 is copied into %13, and printf is called. The beginning of the code is similar to what is done in the obfuscated version, the arguments are stored in local variables, this time the code extends (cast) the i32 variables into i64 variables, then a function called @__YANSOLLVM_VM_Add is called this accepts to i64 variables (for that reason previous variables are extended), result of the function is assigned to %14, this is truncated to i32 and finally printf is called.
Let’s going to see how add operation is applied in this code:
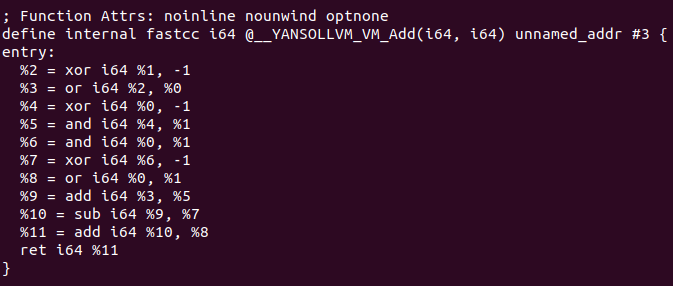
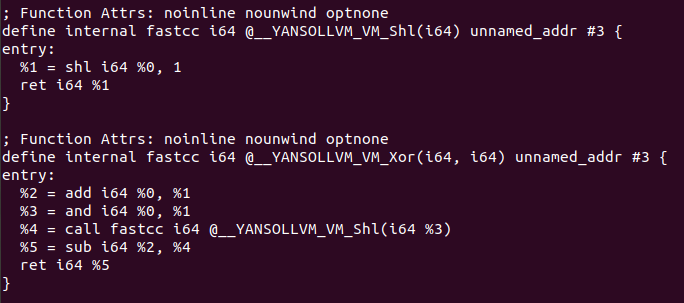
The code transformation is applied in [CreateAdd Function](https://github.com/emc2314/YANSOllvm/blob/master/lib/Transforms/Obfuscate/VM.cpp#L45]. The code presented here just generates this scrambled version of the “add” operation, after that each module will be analyzed with the LLVM pass, and if inside of a function an “add” operation is found, it will be replaced with a cast of its operand and a call to the function with the obfuscated version done with this code. The same happend with the next operations: Sub operation, Arithmetic Shift left, Arithmetic Shift right, Logical Shift left, logical and, logical or and logical xor.
As these operations are obfuscated, it’s possible to execute them apart just to test which kind of output you can have, for doing symbolic execution or evaluate expressions, we can use a framework as Triton, this is a dynamic binary analysis framework as its github points, allows you to do Dynamic Symbolic Execution, dynamic taint analysis, AST representations of code and so on. As we want to check that these obfuscated versions are scrambled versions of simple operations we can use a modified version of the example code in synthetizing_obfuscated_expressions.py, this code simplifies the operation based on an evaluation of the instructions using a serie of test values which should give a given output, for each test of arithmetic or logic operation, it will make some evaluation with different input values, if the output is correct for each one, we can take that a big expression represents a simpler one. First let’s going to see the LLVM IR of the other obfuscation in our example_simple.c.
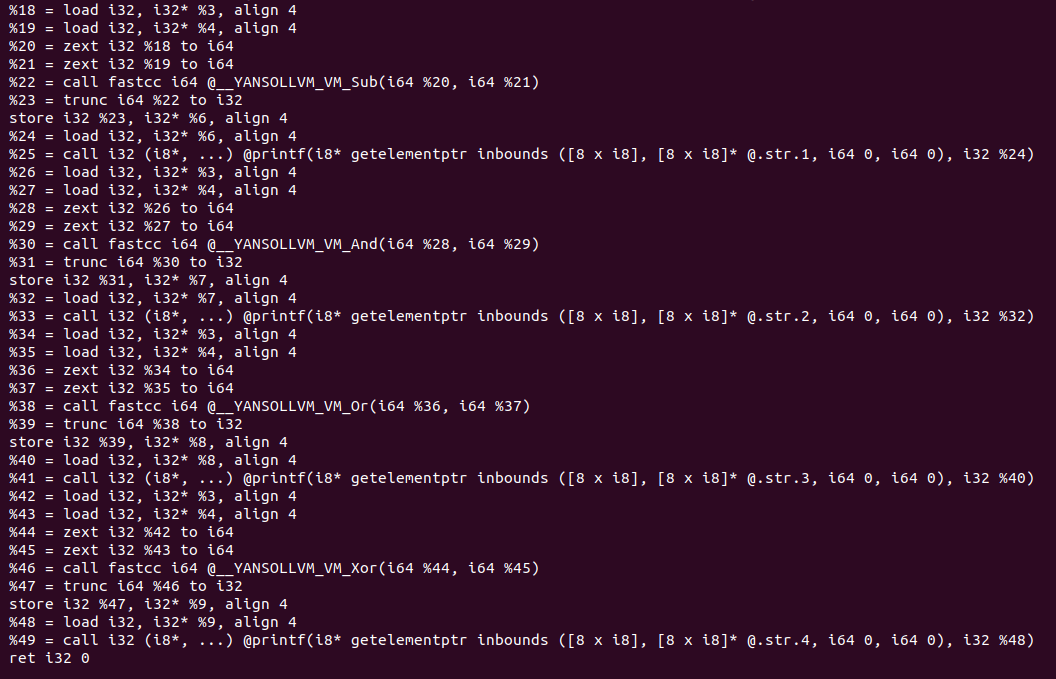

Now let’s going to modify the code from Triton in order to test the equivalences from the obfuscated versions of the simple operations. The modified code can be found in this python file. If we run it, we can see the input values, and the result of the evaluation of given expressions.
These are the different results from the execution:


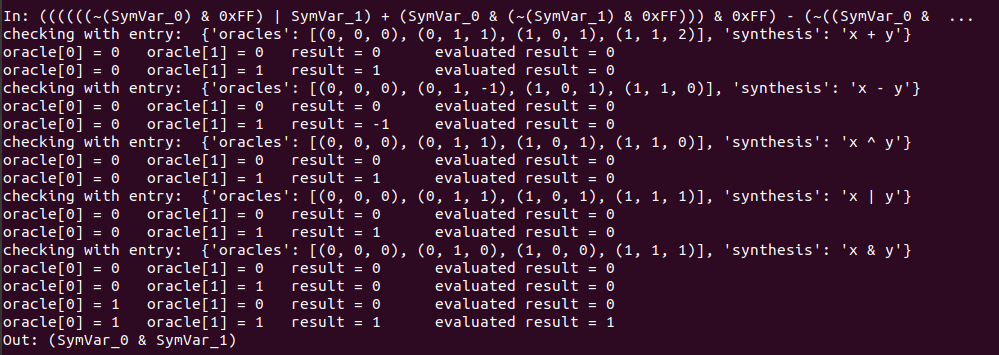
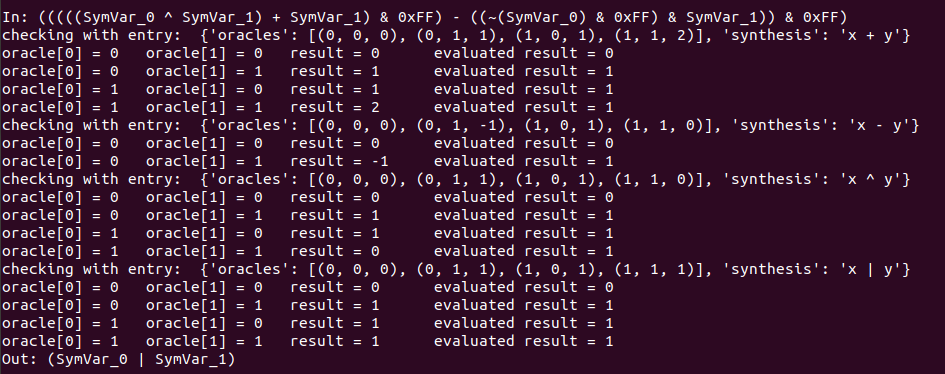
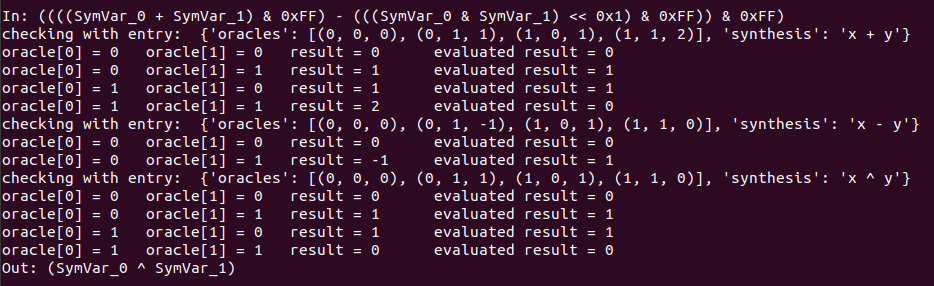
As we can see for each case, it evaluates the expressions with different intputs, finally it checks each output with the expected one, so once the four checks are correct the program tells us the synthesis of the operation. This same thing can be done with symbolic execution and the binary code instead of giving expressions, as done by the code in this file
The execution can be seen in the next picture:
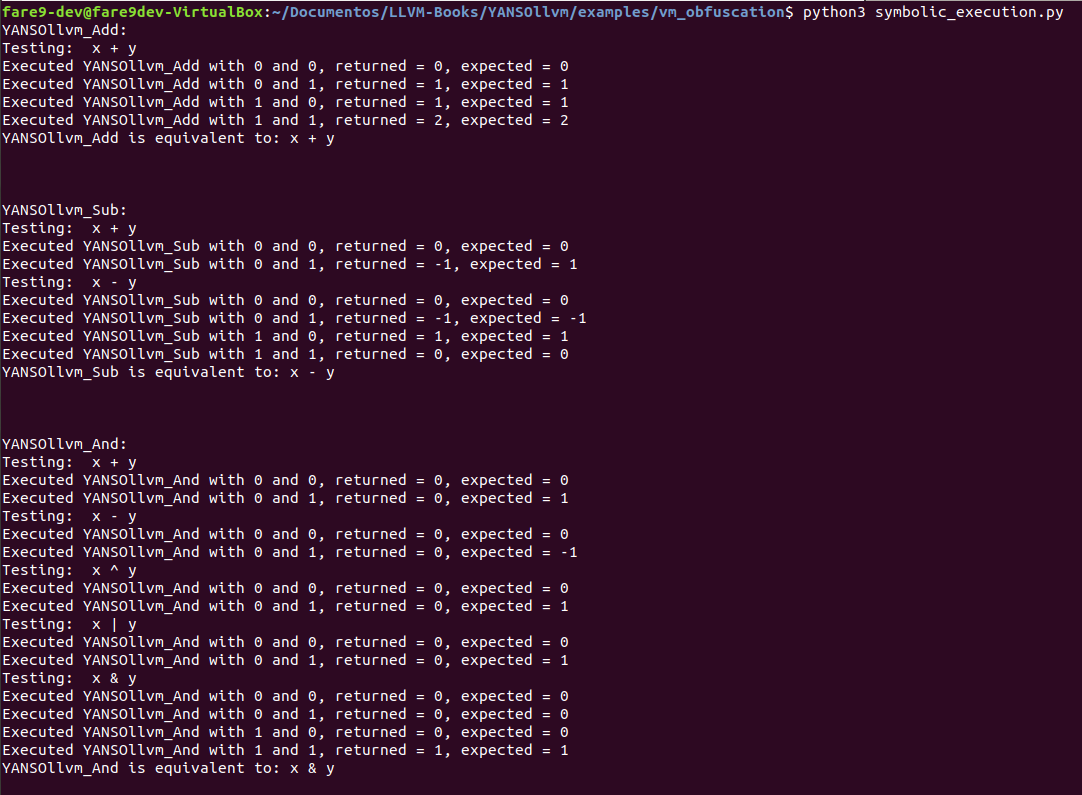
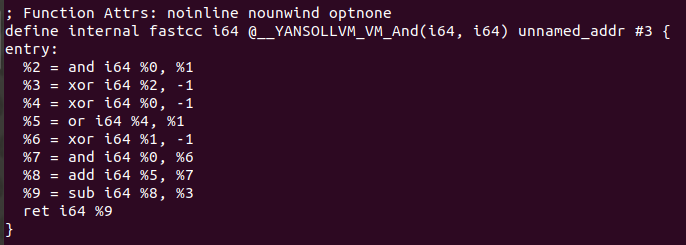
As a final step once we’ve been able to analyze with Triton which kind of operation were these functions, in the same way that the code was generated with a LLVM pass, we can create another pass to deobfuscate the operations, I’m not an expert about LLVM so I’ve only been able to deobfuscate those without calls to other functions, but probably this could be optimized in order to deobfuscate the other calls. To deobfuscate the program we will write a simple FunctionPass that will go through each function instruction, and once it detects the last instruction from one of the methods it will modify that instruction for the simplified one, after that the Dead Code Elimination (-dce) pass will be called to delete the previous code in order to optimize the function and finally have only one instruction. The code for the pass can be found here, and its Makefile here, modify the name of the Makefile and change the paths for gcc and the llvm folder in order to compile the Pass. So if we remember the functions for add, and and or:
Now if we run the opt tool with our pass, and the dead code elimination:

(yanso_test.ll contains the same than previous example_simple) And now if we see the output of the functions:

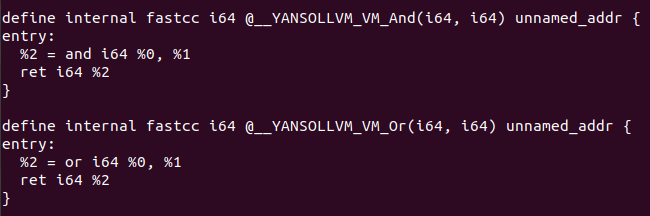
So far it would be the analysis of the -vm option from YANSOllvm how we’ve analyzed the obfuscated operations with Triton, and finally we’ve deobfuscated the generated LLVM IR with a LLVM pass.
Merge.cpp pass
Once I’ve explained the VM option which only replaces different assembly operations for calls to scrambled versions of those operations, we can move on to the Merge option, this option as it says in the source code it merges all those static functions. The static functions in C are those that its scope is limited to its object file, this means that even if we have a declaration in a header file, if we try to use the function from another file the linker will throw an error saying that the reference to the function is not defined. The Merge obfuscation at the beginning will check this, that the functions to merge are static, so the obfuscator doesn’t need to take care about other files, only the one to obfuscate (this pass works for modules). Also another check is done to be sure that the function does not accept a variable number of arguments and the return type is integer, pointer or void. If all these conditions are met the obfuscation append them into a vector, once the pass has all the functions to implement in the switch it has to calculate the parameters to be used in the merged function, these will be separated in 3, those that are 32 bits, those of 64 bits and finally other types of parameters, the number for each one will be taken from the maximum of each merged function. The first parameter of the result function will be always the id for a switch statement, then each call to each function must be modified for a call to the merge function wilth the specific id of execution and with all the necessary parameters. Finally the function is inlined inside of one of the switch-case from the result function, the original function is removed from the final binary.
Let’s gonna see this once the binary is compiled in order to check how is the result, we can see at first glance our function completely clear without any obfuscation applied:
![]()
As the decompiled code shows, it’s a very simple program, it directly applies single operations to two numbers and nothing more, we can see the Control flow graph in the next image:
![]()
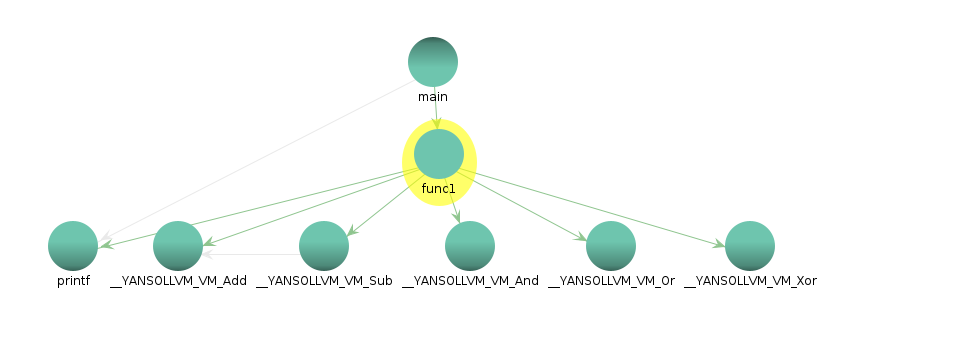
Once we used the VM pass, we had that all of the arithmetic and boolean expressions were resolved to calls to functions which did the same than those operations, so we had the next code:
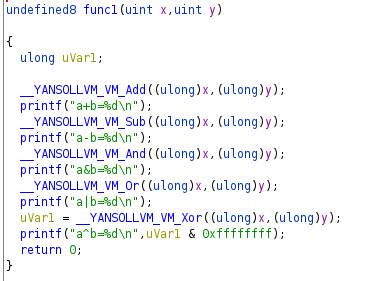
What changed mainly here is the call graph from function1, also if the symbols from the names are removed it will be harder to know what is done inside one of the functions, the next picture shows the call graph: